| MPI2007 license: | 13 | Test date: | Jul-2017 |
|---|---|---|---|
| Test sponsor: | Intel Corporation | Hardware Availability: | Jul-2017 |
| Tested by: | Intel Corporation | Software Availability: | Sep-2017 |
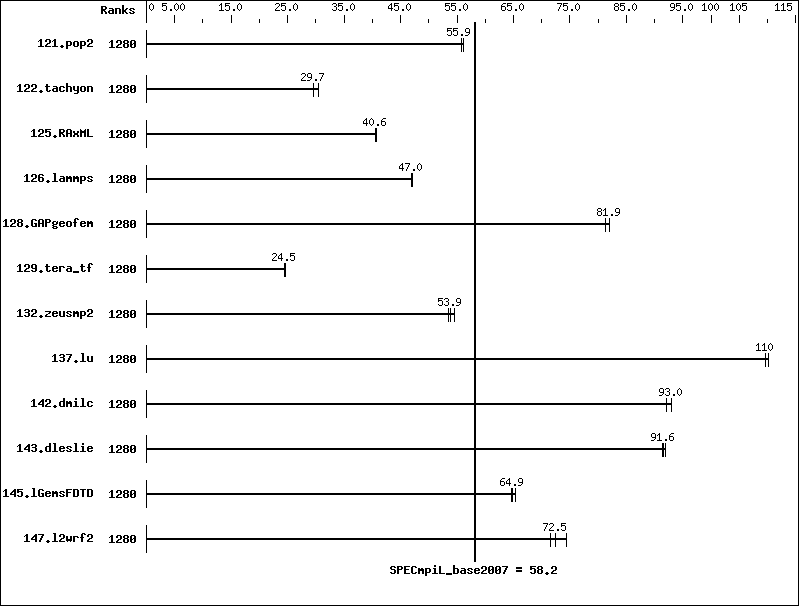
Results Table
| Benchmark | Base | Peak | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ranks | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | Ranks | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | |
| Results appear in the order in which they were run. Bold underlined text indicates a median measurement. | ||||||||||||||
| 121.pop2 | 1280 | 69.6 | 55.9 | 69.7 | 55.8 | 69.3 | 56.1 | |||||||
| 122.tachyon | 1280 | 65.5 | 29.7 | 64.0 | 30.4 | 65.7 | 29.6 | |||||||
| 125.RAxML | 1280 | 71.8 | 40.7 | 72.0 | 40.6 | 72.0 | 40.5 | |||||||
| 126.lammps | 1280 | 52.2 | 47.1 | 52.3 | 47.0 | 52.4 | 46.9 | |||||||
| 128.GAPgeofem | 1280 | 72.4 | 81.9 | 72.3 | 82.1 | 72.9 | 81.4 | |||||||
| 129.tera_tf | 1280 | 44.8 | 24.5 | 44.7 | 24.6 | 44.8 | 24.5 | |||||||
| 132.zeusmp2 | 1280 | 39.6 | 53.6 | 38.9 | 54.5 | 39.4 | 53.9 | |||||||
| 137.lu | 1280 | 38.3 | 110 | 38.1 | 110 | 38.3 | 110 | |||||||
| 142.dmilc | 1280 | 40.0 | 92.0 | 39.6 | 93.0 | 39.6 | 93.1 | |||||||
| 143.dleslie | 1280 | 33.9 | 91.4 | 33.8 | 91.8 | 33.9 | 91.6 | |||||||
| 145.lGemsFDTD | 1280 | 67.4 | 65.4 | 68.0 | 64.9 | 68.1 | 64.7 | |||||||
| 147.l2wrf2 | 1280 | 115 | 71.5 | 113 | 72.5 | 110 | 74.4 | |||||||
| Hardware Summary | |
|---|---|
| Type of System: | Homogeneous |
| Compute Node: | Endeavor Node |
| Interconnects: | Intel Omni-Path Intel Omni-Path |
| File Server Node: | Lustre FS |
| Total Compute Nodes: | 32 |
| Total Chips: | 64 |
| Total Cores: | 1280 |
| Total Threads: | 2560 |
| Total Memory: | 6 TB |
| Base Ranks Run: | 1280 |
| Minimum Peak Ranks: | -- |
| Maximum Peak Ranks: | -- |
| Software Summary | |
|---|---|
| C Compiler: | Intel C++ Composer XE 2017 for Linux Version 17.0.4.196 Build 20170411 |
| C++ Compiler: | Intel C++ Composer XE 2017 for Linux Version 17.0.4.196 Build 20170411 |
| Fortran Compiler: | Intel Fortran Composer XE 2017 for Linux Version 17.0.4.196 Build 20170411 |
| Base Pointers: | 64-bit |
| Peak Pointers: | Not Applicable |
| MPI Library: | Intel MPI Library 17u4 for Linux |
| Other MPI Info: | None |
| Pre-processors: | No |
| Other Software: | None |
Node Description: Endeavor Node
| Hardware | |
|---|---|
| Number of nodes: | 32 |
| Uses of the node: | compute |
| Vendor: | Intel |
| Model: | Intel Server System R2208WFTZS (Intel Xeon Gold 6148, 2.4 GHz) |
| CPU Name: | Intel Xeon Gold 6148 |
| CPU(s) orderable: | 1-2 chips |
| Chips enabled: | 2 |
| Cores enabled: | 40 |
| Cores per chip: | 20 |
| Threads per core: | 2 |
| CPU Characteristics: | Intel Turbo Boost Technology up to 3.7 GHz |
| CPU MHz: | 2400 |
| Primary Cache: | 32 KB I + 32 KB D on chip per core |
| Secondary Cache: | 1 MB I+D on chip per core |
| L3 Cache: | 27.5 MB I+D on chip per chip |
| Other Cache: | None |
| Memory: | 192 GB (12 x 16 GB 2Rx4 DDR4-2666 ECC Registered) |
| Disk Subsystem: | 1 x 800 GB SSD (INTEL SSDSC2BA80) |
| Other Hardware: | None |
| Adapter: | Intel Omni-Path Fabric Adapter 100 series |
| Number of Adapters: | 1 |
| Slot Type: | PCI-Express x16 |
| Data Rate: | 12.5 GB/s |
| Ports Used: | 1 |
| Interconnect Type: | Intel Omni-Path Fabric Adapter 100 series |
| Adapter: | Intel Omni-Path Edge Switch 100 series |
| Number of Adapters: | 1 |
| Slot Type: | PCI-Express x16 |
| Data Rate: | 12.5 GB/s |
| Ports Used: | 1 |
| Interconnect Type: | Intel Omni-Path Fabric Adapter 100 series |
| Software | |
|---|---|
| Adapter: | Intel Omni-Path Fabric Adapter 100 series |
| Adapter Driver: | IFS 10.4 |
| Adapter Firmware: | 0.9-46 |
| Adapter: | Intel Omni-Path Edge Switch 100 series |
| Adapter Driver: | IFS 10.4 |
| Adapter Firmware: | 0.9-46 |
| Operating System: | Oracle Linux Server release 7.3, Kernel 3.10.0-514.6.2.0.1.el7.x86_64.knl1 |
| Local File System: | Linux/xfs |
| Shared File System: | LFS |
| System State: | Multi-User |
| Other Software: | IBM Platform LSF Standard 9.1.1.1 |
Node Description: Lustre FS
| Hardware | |
|---|---|
| Number of nodes: | 11 |
| Uses of the node: | fileserver |
| Vendor: | Intel |
| Model: | Intel Server System R2224GZ4GC4 |
| CPU Name: | Intel Xeon E5-2680 |
| CPU(s) orderable: | 1-2 chips |
| Chips enabled: | 2 |
| Cores enabled: | 16 |
| Cores per chip: | 8 |
| Threads per core: | 2 |
| CPU Characteristics: | Intel Turbo Boost Technology disabled |
| CPU MHz: | 2700 |
| Primary Cache: | 32 KB I + 32 KB D on chip per core |
| Secondary Cache: | 2 MB I+D on chip per chip |
| L3 Cache: | 20 MB I+D on chip per chip |
| Other Cache: | None |
| Memory: | 64 GB (8 x 8GB 1600MHz Reg ECC DDR3) |
| Disk Subsystem: | 2.1 TB |
| Other Hardware: | None |
| Adapter: | Intel Omni-Path Fabric Adapter 100 series |
| Number of Adapters: | 1 |
| Slot Type: | PCI-Express x16 |
| Data Rate: | 12.5 GB/s |
| Ports Used: | 1 |
| Interconnect Type: | Intel Omni-Path Fabric Adapter 100 series |
| Software | |
|---|---|
| Adapter: | Intel Omni-Path Fabric Adapter 100 series |
| Adapter Driver: | IFS 10.4 |
| Adapter Firmware: | 0.9-46 |
| Operating System: | Redhat* Enterprise Linux* Server Release 7.2, Kernel 3.10.0-514.6.2.0.1.el7.x86_64.knl1 |
| Local File System: | None |
| Shared File System: | Lustre FS |
| System State: | Multi-User |
| Other Software: | None |
Interconnect Description: Intel Omni-Path
| Hardware | |
|---|---|
| Vendor: | Intel |
| Model: | Intel Omni-Path 100 series |
| Switch Model: | Intel Omni-Path Edge Switch 100 series |
| Number of Switches: | 24 |
| Number of Ports: | 48 |
| Data Rate: | 12.5 GB/s |
| Firmware: | 0.9-46 |
| Topology: | Fat tree |
| Primary Use: | MPI traffic |
Interconnect Description: Intel Omni-Path
| Hardware | |
|---|---|
| Vendor: | Intel Corporation |
| Model: | Intel Omni-Path 100 series |
| Switch Model: | Intel Omni-Path Edge Switch 100 series |
| Number of Switches: | 1 |
| Number of Ports: | 48 |
| Data Rate: | 12.5 GB/s |
| Firmware: | 0.9-46 |
| Topology: | Fat tree |
| Primary Use: | Cluster File System |
Submit Notes
The config file option 'submit' was used.
General Notes
MPI startup command:
mpiexec.hydra command was used to start MPI jobs.
Software environment:
export I_MPI_COMPATIBILITY=3
export I_MPI_FABRICS=shm:tmi
export I_MPI_HYDRA_PMI_CONNECT=alltoall
Network:
Endeavour Omni-Path fabric consists of 48-port switches = 24 core switches
connected to each leaf of the rack switch.
Job placement:
Each MPI job was assigned to a topologically compact set of nodes, i.e.
the minimal needed number of leaf switches was used for each job = 1 switch
for 40/80/160/320/640 ranks, 2 switches for 1280 and 1980 ranks.
IBM Platform LSF was used for job submission. It has no impact on performance.
Information can be found at: http://www.ibm.com
Base Compiler Invocation
C benchmarks:
| mpiicc |
C++ benchmarks:
| 126.lammps: | mpiicpc |
Fortran benchmarks:
| mpiifort |
Benchmarks using both Fortran and C:
| mpiicc mpiifort |
Base Portability Flags
| 121.pop2: | -DSPEC_MPI_CASE_FLAG |
| 126.lammps: | -DMPICH_IGNORE_CXX_SEEK |