| CPU2006 license: | 11 | Test date: | May-2013 |
|---|---|---|---|
| Test sponsor: | IBM Corporation | Hardware Availability: | Aug-2013 |
| Tested by: | IBM Corporation | Software Availability: | May-2013 |
| Hardware | |
|---|---|
| CPU Name: | POWER7+ |
| CPU Characteristics: | Intelligent Energy Optimization enabled, up to 4.431 GHz |
| CPU MHz: | 4060 |
| FPU: | Integrated |
| CPU(s) enabled: | 32 cores, 8 chips, 4 cores/chip, 4 threads/core |
| CPU(s) orderable: | 16, 32 cores |
| Primary Cache: | 32 KB I + 32 KB D on chip per core |
| Secondary Cache: | 256 KB I+D on chip per core |
| L3 Cache: | 10 MB I+D on chip per core |
| Other Cache: | None |
| Memory: | 256 GB (64 x 4 GB) DDR3 1066 MHz |
| Disk Subsystem: | 1 x 300 GB SAS SFF 15K RPM |
| Other Hardware: | None |
| Software | |
|---|---|
| Operating System: | Red Hat Enterprise Linux Server release 6.4 (ppc64) kernel 2.6.32-358.6.1.el6.ppc64 |
| Compiler: | C/C++/Fortran: Version 4.7.3 of IBM Advance Toolchain 6.0-4 gcc/g++/gfortran compiler |
| Auto Parallel: | No |
| File System: | ext4 |
| System State: | Run level 3 (multi-user) |
| Base Pointers: | 32-bit |
| Peak Pointers: | 32/64-bit |
| Other Software: | -IBM Advance Toolchain 6.0-4 -IBM Mathematical Acceleration Subsystem (MASS) libraries 7.1.0.2 -Post-Link Optimization for Linux on POWER, version 5.6.2-1 |
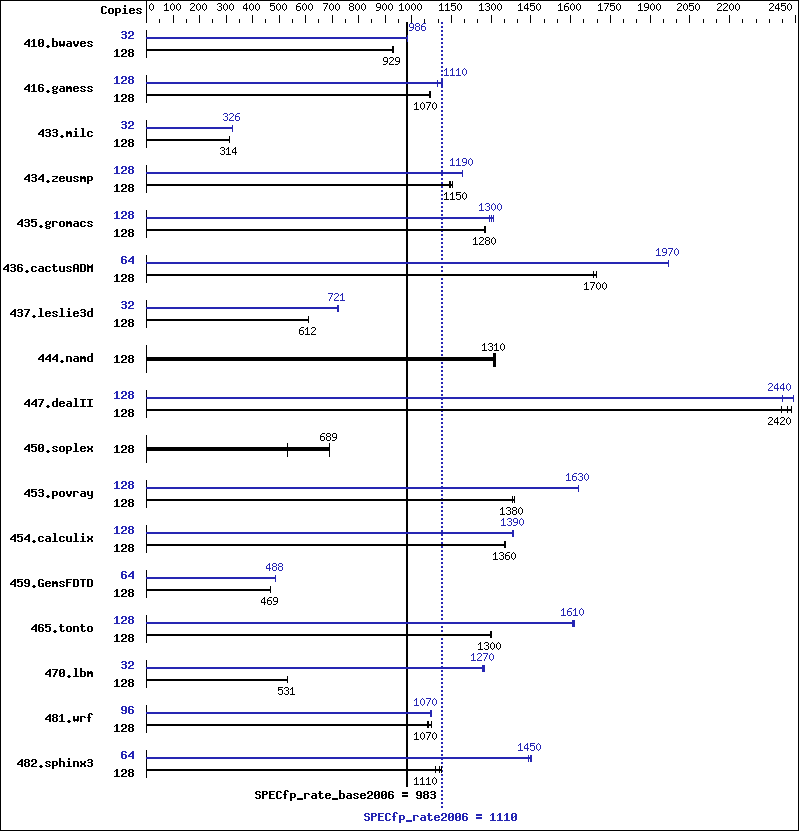
Results Table
| Benchmark | Base | Peak | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Copies | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | Copies | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | |
| Results appear in the order in which they were run. Bold underlined text indicates a median measurement. | ||||||||||||||
| 410.bwaves | 128 | 1874 | 928 | 1870 | 930 | 1872 | 929 | 32 | 441 | 986 | 441 | 987 | 441 | 985 |
| 416.gamess | 128 | 2346 | 1070 | 2341 | 1070 | 2347 | 1070 | 128 | 2284 | 1100 | 2244 | 1120 | 2251 | 1110 |
| 433.milc | 128 | 3739 | 314 | 3730 | 315 | 3738 | 314 | 32 | 902 | 326 | 903 | 325 | 901 | 326 |
| 434.zeusmp | 128 | 1019 | 1140 | 1008 | 1160 | 1015 | 1150 | 128 | 977 | 1190 | 978 | 1190 | 977 | 1190 |
| 435.gromacs | 128 | 717 | 1280 | 714 | 1280 | 715 | 1280 | 128 | 698 | 1310 | 701 | 1300 | 706 | 1290 |
| 436.cactusADM | 128 | 901 | 1700 | 907 | 1690 | 902 | 1700 | 64 | 389 | 1970 | 388 | 1970 | 388 | 1970 |
| 437.leslie3d | 128 | 1964 | 613 | 1966 | 612 | 1968 | 611 | 32 | 417 | 721 | 416 | 723 | 417 | 721 |
| 444.namd | 128 | 783 | 1310 | 780 | 1320 | 782 | 1310 | 128 | 783 | 1310 | 780 | 1320 | 782 | 1310 |
| 447.dealII | 128 | 606 | 2420 | 611 | 2400 | 601 | 2440 | 128 | 610 | 2400 | 599 | 2440 | 600 | 2440 |
| 450.soplex | 128 | 2009 | 531 | 1545 | 691 | 1550 | 689 | 128 | 2009 | 531 | 1545 | 691 | 1550 | 689 |
| 453.povray | 128 | 490 | 1390 | 493 | 1380 | 493 | 1380 | 128 | 417 | 1630 | 418 | 1630 | 418 | 1630 |
| 454.calculix | 128 | 778 | 1360 | 779 | 1360 | 782 | 1350 | 128 | 762 | 1390 | 764 | 1380 | 762 | 1390 |
| 459.GemsFDTD | 128 | 2892 | 470 | 2895 | 469 | 2896 | 469 | 64 | 1391 | 488 | 1390 | 488 | 1391 | 488 |
| 465.tonto | 128 | 971 | 1300 | 969 | 1300 | 967 | 1300 | 128 | 781 | 1610 | 784 | 1610 | 782 | 1610 |
| 470.lbm | 128 | 3314 | 531 | 3314 | 531 | 3310 | 531 | 32 | 345 | 1270 | 347 | 1270 | 345 | 1270 |
| 481.wrf | 128 | 1348 | 1060 | 1330 | 1080 | 1342 | 1070 | 96 | 997 | 1080 | 998 | 1070 | 1001 | 1070 |
| 482.sphinx3 | 128 | 2244 | 1110 | 2287 | 1090 | 2256 | 1110 | 64 | 858 | 1450 | 861 | 1450 | 866 | 1440 |
Compiler Invocation Notes
For more information about IBM Advance Toolchain, including support, see ftp://ftp.unicamp.br/pub/linuxpatch/toolchain/at/redhat/RHEL6/at6.0/release_notes.at6.0-6.0-4.html
Peak Tuning Notes
Post-Link optimization tool used for:
410.bwaves
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
416.gamess
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
429.mcf
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
433.milc
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
434.zeusmp
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
437.leslie3d
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
453.povray
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
454.calculix
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
459.GemsFDTD
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
465.tonto
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
470.lbm
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
481.wrf
with options -O4 -omullX for optimization phase,
and -imullX for instrumentation phase
Submit Notes
The config file option 'submit' was used to assign benchmark copy to specific kernel thread using the "numactl" command (see flags file for details).
Operating System Notes
ulimit -s (stack) set to 1048576. Large pages reserved as follows by root user: echo 8448 > /proc/sys/vm/nr_hugepages The Mathematical Acceleration Subsystem libraries are shipped with IBM XL C/C++ version 12.1 and IBM XL Fortran version 14.1 compiler products. crashkernel was set to 256 MB in /etc/yaboot.conf file.
General Notes
Environment variables set by runspec before the start of the run: HUGETLB_ELFMAP = "RW" HUGETLB_MORECORE = "yes" HUGETLB_VERBOSE = "0" TCMALLOC_MEMFS_MALLOC_PATH = "/libhugetlbfs" XLFRTEOPTS = "intrinthds=1"
Base Compiler Invocation
C benchmarks:
| /opt/at6.0/bin/gcc |
C++ benchmarks:
| /opt/at6.0/bin/g++ |
Fortran benchmarks:
| /opt/at6.0/bin/gfortran |
Benchmarks using both Fortran and C:
| /opt/at6.0/bin/gcc /opt/at6.0/bin/gfortran |
Base Portability Flags
| 447.dealII: | -DSPEC_CPU_LINUX |
| 481.wrf: | -DSPEC_CPU_CASE_FLAG -DSPEC_CPU_LINUX_PPC |
| 482.sphinx3: | -fsigned-char |
Base Optimization Flags
C benchmarks:
C++ benchmarks:
Fortran benchmarks:
Benchmarks using both Fortran and C:
Peak Compiler Invocation
C benchmarks:
| /opt/at6.0/bin/gcc |
C++ benchmarks:
| /opt/at6.0/bin/g++ |
Fortran benchmarks:
| /opt/at6.0/bin/gfortran |
Benchmarks using both Fortran and C:
| /opt/at6.0/bin/gcc /opt/at6.0/bin/gfortran |
Peak Portability Flags
| 436.cactusADM: | -DSPEC_CPU_LP64 |
| 447.dealII: | -DSPEC_CPU_LINUX |
| 459.GemsFDTD: | -DSPEC_CPU_LP64 |
| 470.lbm: | -DSPEC_CPU_LP64 |
| 481.wrf: | -DSPEC_CPU_CASE_FLAG -DSPEC_CPU_LINUX_PPC -DSPEC_CPU_LP64 |
| 482.sphinx3: | -fsigned-char |